AI Model Hosting - Directory w/ AI Reviews
Running AI models in production requires infrastructure optimized for latency, throughput, and cost. Hugging Face's Inference Endpoints and Replicate let developers deploy any model behind a REST API in minutes. Ollama and Together AI make it easy to run open-weight models locally or in the cloud, while Groq's LPU inference chips deliver sub-100ms response times for real-time applications.
 1
4.8
1
4.8
 Hugging Face
Freemium
Free Plan
API
Open Source
Enterprise
Hugging Face is the largest open platform for hosting AI models, with over 500,000 models available for download and deployment. It provides Inference Endpoints for deploying models on dedicated infrastructure, free Inference API for testing, and Spaces for hosting interactive ML applications, makin
Hugging Face
Freemium
Free Plan
API
Open Source
Enterprise
Hugging Face is the largest open platform for hosting AI models, with over 500,000 models available for download and deployment. It provides Inference Endpoints for deploying models on dedicated infrastructure, free Inference API for testing, and Spaces for hosting interactive ML applications, makin
 2
4.8
2
4.8
 OpenAI API Platform
Paid
API
Enterprise
OpenAI hosts and serves its full suite of AI models through managed infrastructure, handling all aspects of GPU provisioning, scaling, and availability. The platform provides endpoints for language models, image generation, speech processing, and embeddings, with the Assistants API offering stateful
OpenAI API Platform
Paid
API
Enterprise
OpenAI hosts and serves its full suite of AI models through managed infrastructure, handling all aspects of GPU provisioning, scaling, and availability. The platform provides endpoints for language models, image generation, speech processing, and embeddings, with the Assistants API offering stateful
 3
4.7
3
4.7
 Ollama
Free
Free Plan
Open Source
Ollama enables local model hosting by serving LLMs through a REST API on the user's own hardware. Its OpenAI-compatible API format allows it to function as a local model server that integrates with development tools, web UIs, and applications, providing self-hosted model infrastructure without cloud
Ollama
Free
Free Plan
Open Source
Ollama enables local model hosting by serving LLMs through a REST API on the user's own hardware. Its OpenAI-compatible API format allows it to function as a local model server that integrates with development tools, web UIs, and applications, providing self-hosted model infrastructure without cloud
 4
4.7
4
4.7
 Replicate
Paid
API
Enterprise
Replicate provides a managed platform for hosting and serving AI models via API. Users can deploy thousands of pre-built open-source models or publish their own using the Cog containerization tool, with automatic GPU provisioning, scaling from zero, and pay-per-use billing that eliminates idle infra
Replicate
Paid
API
Enterprise
Replicate provides a managed platform for hosting and serving AI models via API. Users can deploy thousands of pre-built open-source models or publish their own using the Cog containerization tool, with automatic GPU provisioning, scaling from zero, and pay-per-use billing that eliminates idle infra
 5
4.6
5
4.6
 Together AI
Paid
API
Enterprise
Together AI hosts and serves hundreds of open-source AI models on optimized infrastructure. Developers can deploy models through the shared inference API for cost-effective serving or provision dedicated endpoints for guaranteed capacity, with the platform handling all infrastructure management.
Together AI
Paid
API
Enterprise
Together AI hosts and serves hundreds of open-source AI models on optimized infrastructure. Developers can deploy models through the shared inference API for cost-effective serving or provision dedicated endpoints for guaranteed capacity, with the platform handling all infrastructure management.
 6
4.6
6
4.6
 Anthropic API
Paid
API
Enterprise
Anthropic hosts and serves all Claude models through its managed API infrastructure, handling GPU provisioning, scaling, and reliability. The API is also available through Amazon Bedrock and Google Cloud Vertex AI, giving developers multiple hosting options for accessing Claude models in their prefe
Anthropic API
Paid
API
Enterprise
Anthropic hosts and serves all Claude models through its managed API infrastructure, handling GPU provisioning, scaling, and reliability. The API is also available through Amazon Bedrock and Google Cloud Vertex AI, giving developers multiple hosting options for accessing Claude models in their prefe
 7
4.4
7
4.4
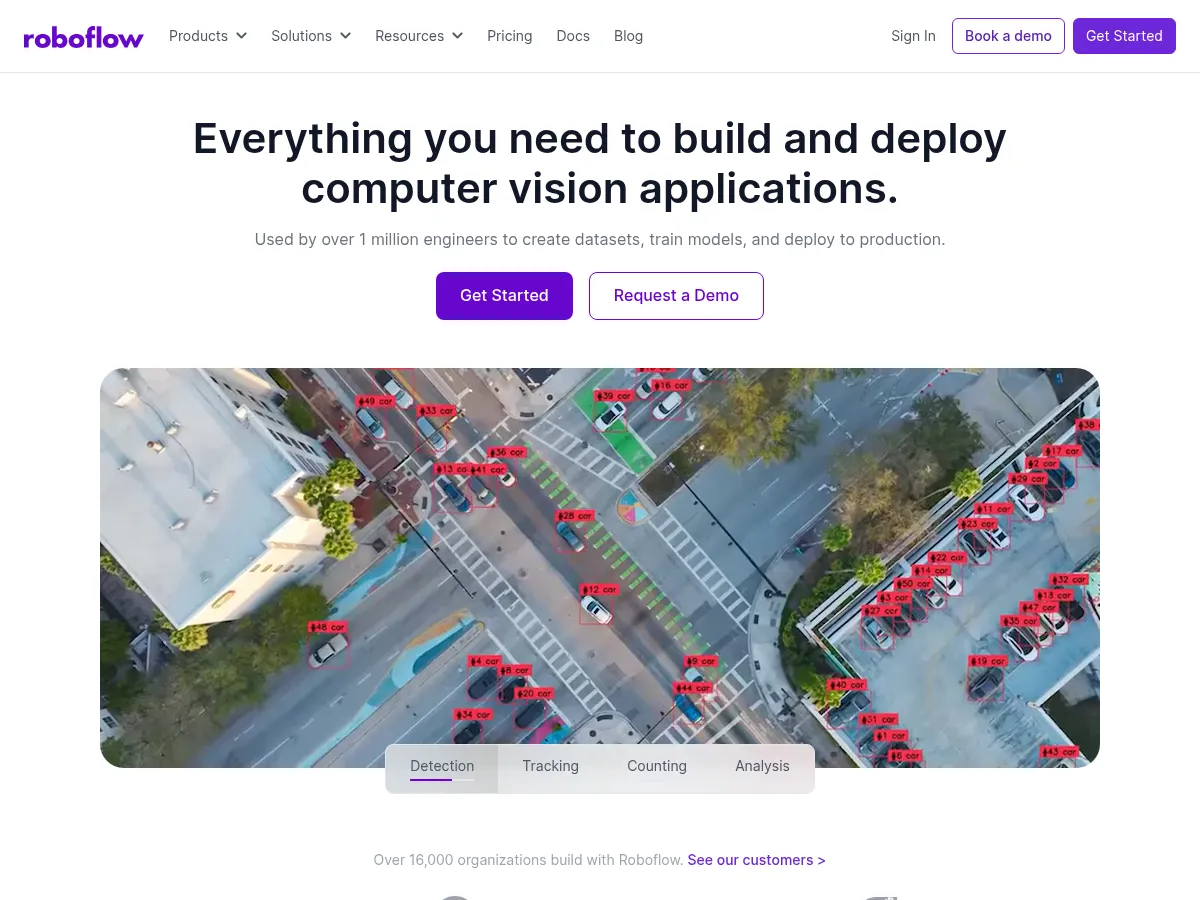
 Roboflow
Freemium
Free Plan
API
Open Source
Enterprise
Roboflow provides hosted inference APIs for deploying computer vision models in production, with options for cloud hosting, edge deployment on devices like NVIDIA Jetson and Raspberry Pi, and self-hosted inference through the open-source Roboflow Inference server. This flexibility supports deploymen
Roboflow
Freemium
Free Plan
API
Open Source
Enterprise
Roboflow provides hosted inference APIs for deploying computer vision models in production, with options for cloud hosting, edge deployment on devices like NVIDIA Jetson and Raspberry Pi, and self-hosted inference through the open-source Roboflow Inference server. This flexibility supports deploymen
 8
4.4
8
4.4
 Databricks
Paid
API
Enterprise
Databricks offers model serving through Mosaic AI, providing managed endpoints for deploying machine learning models and foundation models in production. The platform supports real-time and batch inference, automatic scaling, A/B testing, and model monitoring, along with Foundation Model APIs for ac
Databricks
Paid
API
Enterprise
Databricks offers model serving through Mosaic AI, providing managed endpoints for deploying machine learning models and foundation models in production. The platform supports real-time and batch inference, automatic scaling, A/B testing, and model monitoring, along with Foundation Model APIs for ac
 9
4.4
9
4.4
 Groq
Freemium
Free Plan
API
Enterprise
Groq hosts and serves open-source AI models on its custom LPU hardware, providing managed inference infrastructure that delivers industry-leading speed. Organizations can access models through the shared API or deploy dedicated GroqRack systems for private, high-throughput model serving.
Groq
Freemium
Free Plan
API
Enterprise
Groq hosts and serves open-source AI models on its custom LPU hardware, providing managed inference infrastructure that delivers industry-leading speed. Organizations can access models through the shared API or deploy dedicated GroqRack systems for private, high-throughput model serving.
 10
4.2
10
4.2
 Google AI Studio
Free
Free Plan
API
Enterprise
Google AI Studio serves as a managed hosting platform for Gemini models, providing free-tier inference endpoints that developers can use immediately. Google handles all infrastructure, scaling, and availability, with the option to transition to Vertex AI for dedicated enterprise-grade model hosting
Google AI Studio
Free
Free Plan
API
Enterprise
Google AI Studio serves as a managed hosting platform for Gemini models, providing free-tier inference endpoints that developers can use immediately. Google handles all infrastructure, scaling, and availability, with the option to transition to Vertex AI for dedicated enterprise-grade model hosting
 11
4.0
11
4.0
 Scale AI
Paid
API
Enterprise
Scale AI's Generative AI Platform enables enterprises to build, test, and deploy LLM-powered applications with tools for prompt engineering, model evaluation, fine-tuning data management, and application development. The platform supports the full lifecycle from model selection and customization thr
Scale AI
Paid
API
Enterprise
Scale AI's Generative AI Platform enables enterprises to build, test, and deploy LLM-powered applications with tools for prompt engineering, model evaluation, fine-tuning data management, and application development. The platform supports the full lifecycle from model selection and customization thr