เกณฑ์มาตรฐาน LLM - ไดเรกทอรีพร้อมรีวิว AI
การเลือก LLM ที่เหมาะสมกับงานต้องอาศัยการเปรียบเทียบอย่างเข้มงวดในหลายมิติ เช่น การให้เหตุผล การเขียนโค้ด ความสามารถหลายภาษา และต้นทุน LMSYS Chatbot Arena ใช้การจัดอันดับความชอบของมนุษย์จากการระดมความคิดเห็นเพื่อจัดอันดับโมเดลในงานแบบปลายเปิด HELM ให้ชุดเกณฑ์มาตรฐานที่ได้มาตรฐานสำหรับการเปรียบเทียบทางวิชาการและอุตสาหกรรม ขณะที่ Hugging Face Open LLM Leaderboard ติดตามประสิทธิภาพของโมเดลโอเพนซอร์ส Artificial Analysis เพิ่มเมตริกโครงสร้างพื้นฐาน เช่น ปริมาณงานและความหน่วง เข้าไปในภาพการประเมิน
 1
4.9
1
4.9
 HELM
ฟรี
แผนฟรี
โอเพ่นซอร์ส
HELM by Stanford ประเมินแบบจำลองภาษาในหลายสิบสถานการณ์ โดยวัดความแม่นยำ ความทนทาน และความยุติธรรม
HELM
ฟรี
แผนฟรี
โอเพ่นซอร์ส
HELM by Stanford ประเมินแบบจำลองภาษาในหลายสิบสถานการณ์ โดยวัดความแม่นยำ ความทนทาน และความยุติธรรม
 2
4.9
LMSYS Chatbot Arena
ฟรี
แผนฟรี
โอเพ่นซอร์ส
LMSYS Chatbot Arena is a crowdsourced LLM evaluation platform developed by LMSYS Org that ranks language models through blind, randomized head-to-head battles judged by human users. Visitors submit prompts and vote on anonymous model outputs, with results aggregated into an Elo-style leaderboard tha
2
4.9
LMSYS Chatbot Arena
ฟรี
แผนฟรี
โอเพ่นซอร์ส
LMSYS Chatbot Arena is a crowdsourced LLM evaluation platform developed by LMSYS Org that ranks language models through blind, randomized head-to-head battles judged by human users. Visitors submit prompts and vote on anonymous model outputs, with results aggregated into an Elo-style leaderboard tha
 3
4.8
3
4.8
 Hugging Face Open LLM Leaderboard
ฟรี
แผนฟรี
API
โอเพ่นซอร์ส
The Open LLM Leaderboard by Hugging Face is a comprehensive benchmark tracking platform that evaluates open-source language models across standardized academic benchmarks. The leaderboard automatically runs models through evaluation suites including MMLU, ARC, HellaSwag, TruthfulQA, Winogrande, and
Hugging Face Open LLM Leaderboard
ฟรี
แผนฟรี
API
โอเพ่นซอร์ส
The Open LLM Leaderboard by Hugging Face is a comprehensive benchmark tracking platform that evaluates open-source language models across standardized academic benchmarks. The leaderboard automatically runs models through evaluation suites including MMLU, ARC, HellaSwag, TruthfulQA, Winogrande, and
 4
4.7
4
4.7
 Artificial Analysis
ฟรี
แผนฟรี
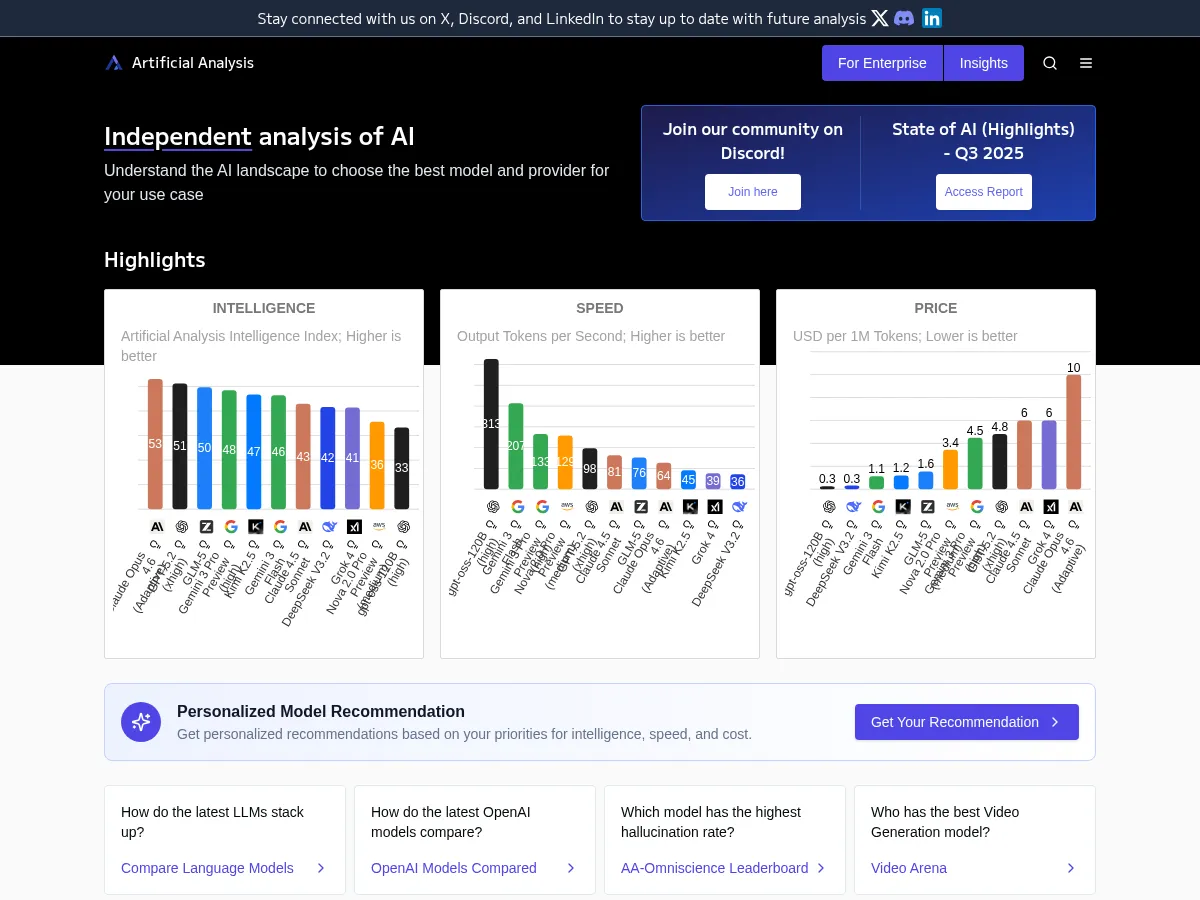
Artificial Analysis ประเมินแบบจำเป็นเฉพาะของโมเดล AI ด้านคุณภาพ ความเร็ว ราคา และปริมานงาน โดยเปรียบเทียบผู้ให้บริการ API
Artificial Analysis
ฟรี
แผนฟรี
Artificial Analysis ประเมินแบบจำเป็นเฉพาะของโมเดล AI ด้านคุณภาพ ความเร็ว ราคา และปริมานงาน โดยเปรียบเทียบผู้ให้บริการ API
 5
4.4
5
4.4
 Evalverse
ฟรี
แผนฟรี
โอเพ่นซอร์ส
Evalverse เป็นกรอบการประเมิน LLM แบบเปิดแหล่งและรวมศูนย์ ซึ่งรวมชุดเกณฑ์มาตรฐานหลายชุดในอินเทอร์เฟซเดียว
Evalverse
ฟรี
แผนฟรี
โอเพ่นซอร์ส
Evalverse เป็นกรอบการประเมิน LLM แบบเปิดแหล่งและรวมศูนย์ ซึ่งรวมชุดเกณฑ์มาตรฐานหลายชุดในอินเทอร์เฟซเดียว