Hosting di modelli AI - Directory con recensioni AI
Eseguire modelli AI in produzione richiede un'infrastruttura ottimizzata per latenza, throughput e costi. Gli Inference Endpoints di Hugging Face e Replicate consentono agli sviluppatori di distribuire qualsiasi modello dietro un'API REST in pochi minuti. Ollama e Together AI semplificano l'esecuzione di modelli a pesi aperti in locale o nel cloud, mentre i chip di inferenza LPU di Groq offrono tempi di risposta inferiori a 100 ms per applicazioni in tempo reale.
 1
4.8
1
4.8
 Hugging Face
Freemium
Piano gratuito
API
Open Source
Enterprise
Hugging Face è la piattaforma aperta più grande per l'hosting di modelli AI, con oltre 500.000 modelli disponibili per il download e la distribuzione. Fornisce Inference Endpoints per distribuire modelli su infrastrutture dedicate, API Inference gratuita per test e Spaces per ospitare applicazioni
Hugging Face
Freemium
Piano gratuito
API
Open Source
Enterprise
Hugging Face è la piattaforma aperta più grande per l'hosting di modelli AI, con oltre 500.000 modelli disponibili per il download e la distribuzione. Fornisce Inference Endpoints per distribuire modelli su infrastrutture dedicate, API Inference gratuita per test e Spaces per ospitare applicazioni
 2
4.8
2
4.8
 OpenAI API Platform
A pagamento
API
Enterprise
OpenAI ospita e fornisce la sua intera suite di modelli AI attraverso infrastrutture gestite, gestendo tutti gli aspetti del provisioning della GPU, del ridimensionamento e della disponibilità. La piattaforma fornisce endpoint per modelli linguistici, generazione di immagini, elaborazione vocale e
OpenAI API Platform
A pagamento
API
Enterprise
OpenAI ospita e fornisce la sua intera suite di modelli AI attraverso infrastrutture gestite, gestendo tutti gli aspetti del provisioning della GPU, del ridimensionamento e della disponibilità. La piattaforma fornisce endpoint per modelli linguistici, generazione di immagini, elaborazione vocale e
 3
4.7
3
4.7
 Ollama
Gratuito
Piano gratuito
Open Source
Ollama consente l'hosting locale di modelli servendo LLM attraverso un'API REST sull'hardware dell'utente. Il suo formato API compatibile con OpenAI le consente di funzionare come server di modelli locale che si integra con strumenti di sviluppo, UI web e applicazioni, fornendo infrastruttura di mod
Ollama
Gratuito
Piano gratuito
Open Source
Ollama consente l'hosting locale di modelli servendo LLM attraverso un'API REST sull'hardware dell'utente. Il suo formato API compatibile con OpenAI le consente di funzionare come server di modelli locale che si integra con strumenti di sviluppo, UI web e applicazioni, fornendo infrastruttura di mod
 4
4.7
4
4.7
 Replicate
A pagamento
API
Enterprise
Replicate fornisce una piattaforma gestita per l'hosting e la distribuzione di modelli di AI tramite API. Gli utenti possono distribuire migliaia di modelli open-source pre-costruiti o pubblicare i propri utilizzando lo strumento di containerizzazione Cog, con provisioning automatico della GPU, scal
Replicate
A pagamento
API
Enterprise
Replicate fornisce una piattaforma gestita per l'hosting e la distribuzione di modelli di AI tramite API. Gli utenti possono distribuire migliaia di modelli open-source pre-costruiti o pubblicare i propri utilizzando lo strumento di containerizzazione Cog, con provisioning automatico della GPU, scal
 5
4.6
5
4.6
 Together AI
A pagamento
API
Enterprise
Together AI ospita e serve centinaia di modelli di intelligenza artificiale open-source su infrastrutture ottimizzate. Gli sviluppatori possono distribuire modelli attraverso l'API di inferenza condivisa per una distribuzione economica o provisioning di endpoint dedicati per capacità garantita, con
Together AI
A pagamento
API
Enterprise
Together AI ospita e serve centinaia di modelli di intelligenza artificiale open-source su infrastrutture ottimizzate. Gli sviluppatori possono distribuire modelli attraverso l'API di inferenza condivisa per una distribuzione economica o provisioning di endpoint dedicati per capacità garantita, con
 6
4.6
6
4.6
 Anthropic API
A pagamento
API
Enterprise
Anthropic ospita e fornisce tutti i modelli Claude attraverso la sua infrastruttura API gestita, gestendo il provisioning della GPU, il scaling e l'affidabilità. L'API è disponibile anche tramite Amazon Bedrock e Google Cloud Vertex AI, offrendo ai sviluppatori più opzioni di hosting per accedere
Anthropic API
A pagamento
API
Enterprise
Anthropic ospita e fornisce tutti i modelli Claude attraverso la sua infrastruttura API gestita, gestendo il provisioning della GPU, il scaling e l'affidabilità. L'API è disponibile anche tramite Amazon Bedrock e Google Cloud Vertex AI, offrendo ai sviluppatori più opzioni di hosting per accedere
 7
4.4
7
4.4
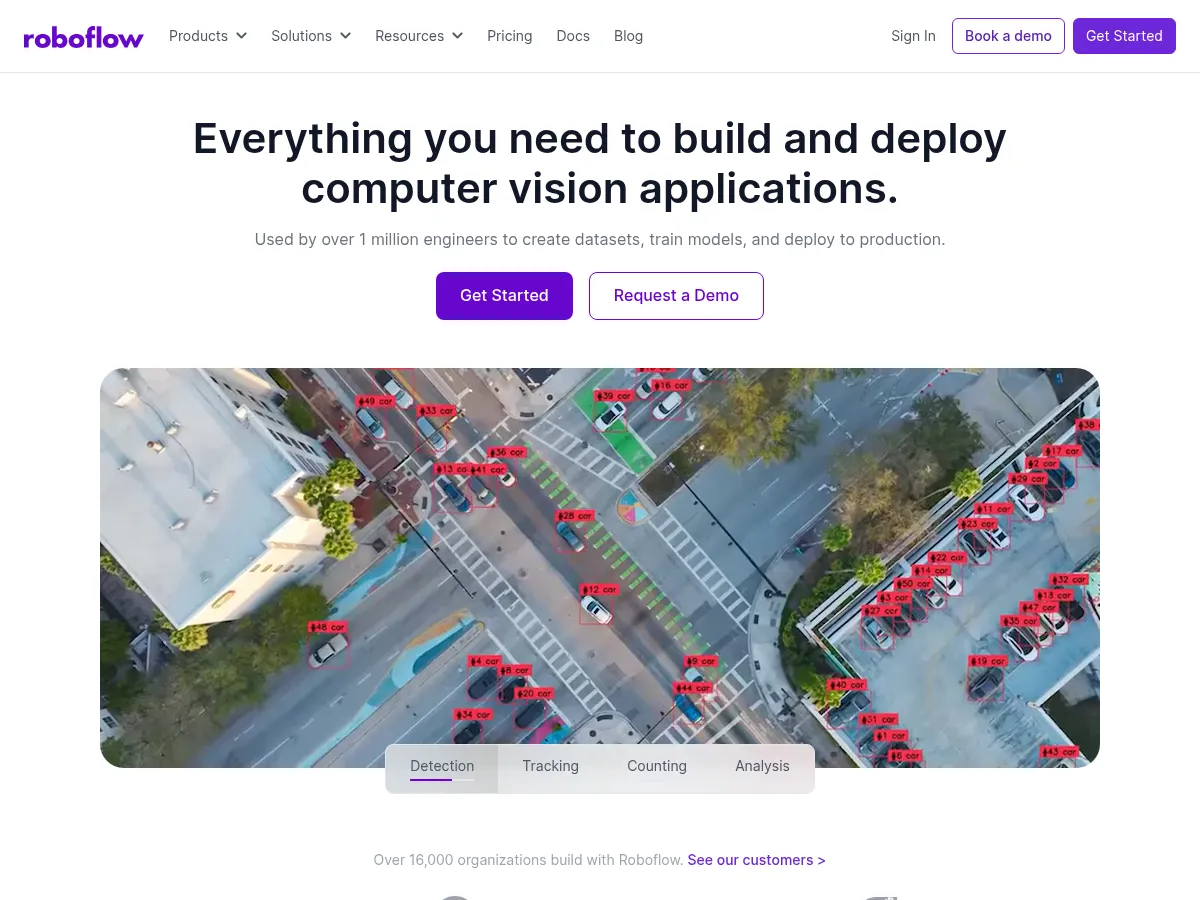
 Roboflow
Freemium
Piano gratuito
API
Open Source
Enterprise
Roboflow fornisce API di inferenza ospitate per la distribuzione di modelli di visione artificiale in produzione, con opzioni per l'hosting nel cloud, la distribuzione edge su dispositivi come NVIDIA Jetson e Raspberry Pi, e l'inferenza auto-ospitata attraverso il server Roboflow Inference open-sour
Roboflow
Freemium
Piano gratuito
API
Open Source
Enterprise
Roboflow fornisce API di inferenza ospitate per la distribuzione di modelli di visione artificiale in produzione, con opzioni per l'hosting nel cloud, la distribuzione edge su dispositivi come NVIDIA Jetson e Raspberry Pi, e l'inferenza auto-ospitata attraverso il server Roboflow Inference open-sour
 8
4.4
8
4.4
 Databricks
A pagamento
API
Enterprise
Databricks offre model serving attraverso Mosaic AI, fornendo endpoint gestiti per la distribuzione di modelli di machine learning e foundation model in produzione. La piattaforma supporta inferenza in tempo reale e batch, scalabilità automatica, test A/B e monitoraggio dei modelli, insieme alle Fo
Databricks
A pagamento
API
Enterprise
Databricks offre model serving attraverso Mosaic AI, fornendo endpoint gestiti per la distribuzione di modelli di machine learning e foundation model in produzione. La piattaforma supporta inferenza in tempo reale e batch, scalabilità automatica, test A/B e monitoraggio dei modelli, insieme alle Fo
 9
4.4
9
4.4
 Groq
Freemium
Piano gratuito
API
Enterprise
Groq ospita e serve modelli di IA open-source sul suo hardware LPU personalizzato, fornendo infrastruttura di inferenza gestita che offre velocità leader nel settore. Le organizzazioni possono accedere ai modelli attraverso l'API condivisa o distribuire sistemi GroqRack dedicati per il servizio di
Groq
Freemium
Piano gratuito
API
Enterprise
Groq ospita e serve modelli di IA open-source sul suo hardware LPU personalizzato, fornendo infrastruttura di inferenza gestita che offre velocità leader nel settore. Le organizzazioni possono accedere ai modelli attraverso l'API condivisa o distribuire sistemi GroqRack dedicati per il servizio di
 10
4.2
10
4.2
 Google AI Studio
Gratuito
Piano gratuito
API
Enterprise
Google AI Studio funge da piattaforma di hosting gestito per i modelli Gemini, fornendo endpoint di inferenza del livello gratuito che gli sviluppatori possono utilizzare immediatamente. Google gestisce tutta l'infrastruttura, il ridimensionamento e la disponibilità, con l'opzione di passare a Vert
Google AI Studio
Gratuito
Piano gratuito
API
Enterprise
Google AI Studio funge da piattaforma di hosting gestito per i modelli Gemini, fornendo endpoint di inferenza del livello gratuito che gli sviluppatori possono utilizzare immediatamente. Google gestisce tutta l'infrastruttura, il ridimensionamento e la disponibilità, con l'opzione di passare a Vert
 11
4.0
11
4.0
 Scale AI
A pagamento
API
Enterprise
La Piattaforma Generative AI di Scale AI consente alle aziende di costruire, testare e distribuire applicazioni alimentate da LLM con strumenti per l'ingegneria dei prompt, la valutazione dei modelli, la gestione dei dati di fine-tuning e lo sviluppo di applicazioni. La piattaforma supporta l'intero
Scale AI
A pagamento
API
Enterprise
La Piattaforma Generative AI di Scale AI consente alle aziende di costruire, testare e distribuire applicazioni alimentate da LLM con strumenti per l'ingegneria dei prompt, la valutazione dei modelli, la gestione dei dati di fine-tuning e lo sviluppo di applicazioni. La piattaforma supporta l'intero