Hospedagem de Modelos de IA - Diretório com Avaliações de IA
Executar modelos de IA em produção exige uma infraestrutura otimizada para latência, throughput e custo. Os Inference Endpoints da Hugging Face e o Replicate permitem que desenvolvedores implantem qualquer modelo por trás de uma API REST em minutos. Ollama e Together AI facilitam a execução de modelos de pesos abertos localmente ou na nuvem, enquanto os chips de inferência LPU da Groq entregam tempos de resposta abaixo de 100 ms para aplicações em tempo real.
 1
4.8
1
4.8
 Hugging Face
Freemium
Plano Gratuito
API
Código Aberto
Empresarial
O Hugging Face é a maior plataforma aberta para hospedagem de modelos de IA, com mais de 500.000 modelos disponíveis para download e implantação. Fornece Inference Endpoints para implantar modelos em infraestrutura dedicada, Inference API gratuita para testes e Spaces para hospedar aplicações
Hugging Face
Freemium
Plano Gratuito
API
Código Aberto
Empresarial
O Hugging Face é a maior plataforma aberta para hospedagem de modelos de IA, com mais de 500.000 modelos disponíveis para download e implantação. Fornece Inference Endpoints para implantar modelos em infraestrutura dedicada, Inference API gratuita para testes e Spaces para hospedar aplicações
 2
4.8
2
4.8
 OpenAI API Platform
Pago
API
Empresarial
A OpenAI hospeda e fornece seu conjunto completo de modelos de IA através de infraestrutura gerenciada, tratando todos os aspectos do provisionamento de GPU, dimensionamento e disponibilidade. A plataforma fornece endpoints para modelos de linguagem, geração de imagens, processamento de fala e em
OpenAI API Platform
Pago
API
Empresarial
A OpenAI hospeda e fornece seu conjunto completo de modelos de IA através de infraestrutura gerenciada, tratando todos os aspectos do provisionamento de GPU, dimensionamento e disponibilidade. A plataforma fornece endpoints para modelos de linguagem, geração de imagens, processamento de fala e em
 3
4.7
3
4.7
 Ollama
Gratuito
Plano Gratuito
Código Aberto
A Ollama permite hospedagem de modelos locais ao servir LLMs através de uma API REST no hardware do próprio usuário. Seu formato de API compatível com OpenAI permite que funcione como um servidor de modelo local que se integra com ferramentas de desenvolvimento, UIs web e aplicações, fornecend
Ollama
Gratuito
Plano Gratuito
Código Aberto
A Ollama permite hospedagem de modelos locais ao servir LLMs através de uma API REST no hardware do próprio usuário. Seu formato de API compatível com OpenAI permite que funcione como um servidor de modelo local que se integra com ferramentas de desenvolvimento, UIs web e aplicações, fornecend
 4
4.7
4
4.7
 Replicate
Pago
API
Empresarial
O Replicate fornece uma plataforma gerenciada para hospedagem e disponibilização de modelos de IA via API. Os usuários podem implantar milhares de modelos de código aberto pré-construídos ou publicar os seus próprios usando a ferramenta de containerização Cog, com provisionamento automátic
Replicate
Pago
API
Empresarial
O Replicate fornece uma plataforma gerenciada para hospedagem e disponibilização de modelos de IA via API. Os usuários podem implantar milhares de modelos de código aberto pré-construídos ou publicar os seus próprios usando a ferramenta de containerização Cog, com provisionamento automátic
 5
4.6
5
4.6
 Together AI
Pago
API
Empresarial
Together AI hospeda e serve centenas de modelos de IA de código aberto em infraestrutura otimizada. Desenvolvedores podem implantar modelos através da API de inferência compartilhada para servimento econômico ou provisionar endpoints dedicados para capacidade garantida, com a plataforma gerencia
Together AI
Pago
API
Empresarial
Together AI hospeda e serve centenas de modelos de IA de código aberto em infraestrutura otimizada. Desenvolvedores podem implantar modelos através da API de inferência compartilhada para servimento econômico ou provisionar endpoints dedicados para capacidade garantida, com a plataforma gerencia
 6
4.6
6
4.6
 Anthropic API
Pago
API
Empresarial
A Anthropic hospeda e serve todos os modelos Claude através de sua infraestrutura de API gerenciada, tratando provisionamento de GPU, escalabilidade e confiabilidade. A API também está disponível através do Amazon Bedrock e Google Cloud Vertex AI, dando aos desenvolvedores múltiplas opções d
Anthropic API
Pago
API
Empresarial
A Anthropic hospeda e serve todos os modelos Claude através de sua infraestrutura de API gerenciada, tratando provisionamento de GPU, escalabilidade e confiabilidade. A API também está disponível através do Amazon Bedrock e Google Cloud Vertex AI, dando aos desenvolvedores múltiplas opções d
 7
4.4
7
4.4
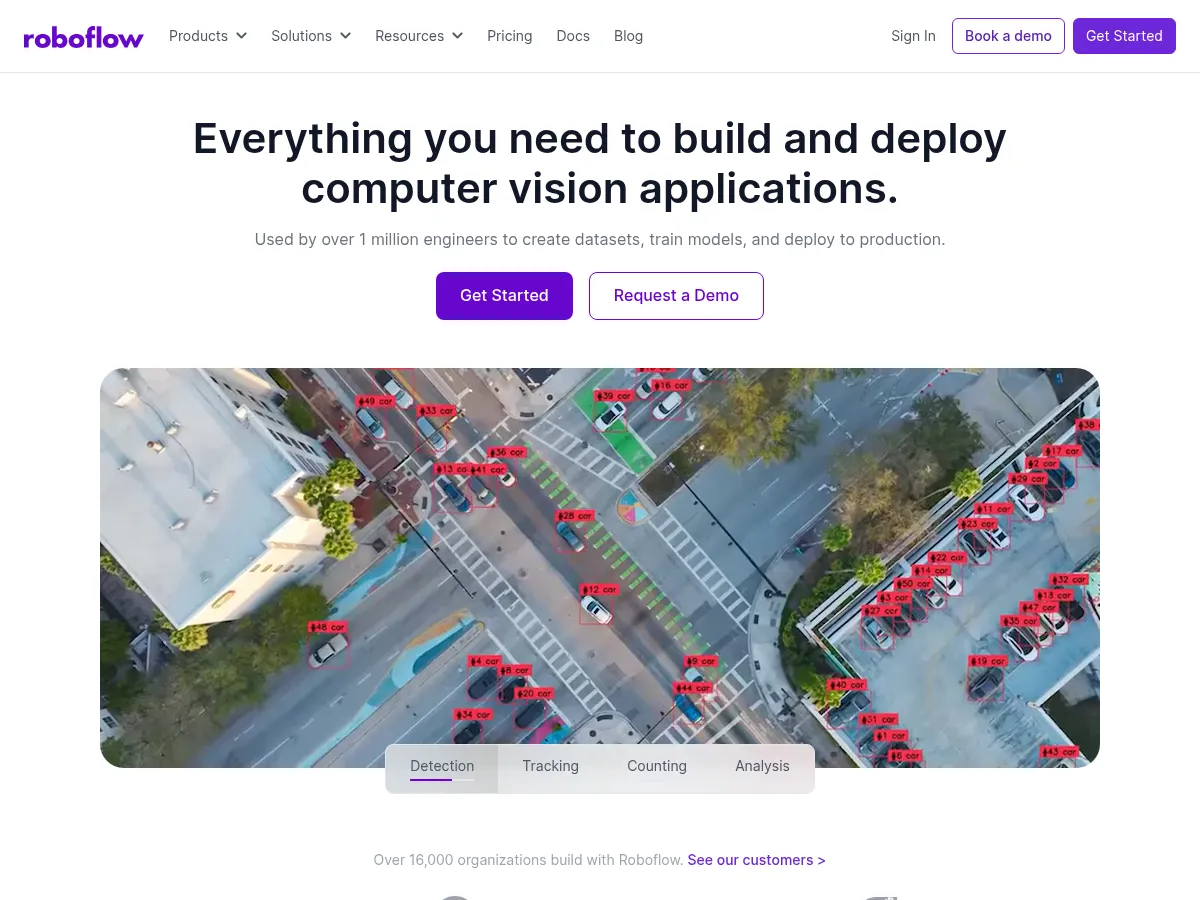
 Roboflow
Freemium
Plano Gratuito
API
Código Aberto
Empresarial
O Roboflow fornece APIs de inferência hospedadas para implementar modelos de visão computacional em produção, com opções para hospedagem em nuvem, implementação em dispositivos como NVIDIA Jetson e Raspberry Pi, e inferência auto-hospedada através do servidor Roboflow Inference de código
Roboflow
Freemium
Plano Gratuito
API
Código Aberto
Empresarial
O Roboflow fornece APIs de inferência hospedadas para implementar modelos de visão computacional em produção, com opções para hospedagem em nuvem, implementação em dispositivos como NVIDIA Jetson e Raspberry Pi, e inferência auto-hospedada através do servidor Roboflow Inference de código
 8
4.4
8
4.4
 Databricks
Pago
API
Empresarial
O Databricks oferece model serving através do Mosaic AI, fornecendo endpoints gerenciados para implantar modelos de aprendizado de máquina e modelos de fundação em produção. A plataforma suporta inferência em tempo real e em lote, dimensionamento automático, testes A/B e monitoramento de mod
Databricks
Pago
API
Empresarial
O Databricks oferece model serving através do Mosaic AI, fornecendo endpoints gerenciados para implantar modelos de aprendizado de máquina e modelos de fundação em produção. A plataforma suporta inferência em tempo real e em lote, dimensionamento automático, testes A/B e monitoramento de mod
 9
4.4
9
4.4
 Groq
Freemium
Plano Gratuito
API
Empresarial
A Groq hospeda e serve modelos de IA de código aberto em seu hardware LPU customizado, fornecendo infraestrutura de inferência gerenciada que entrega velocidade líder da indústria. As organizações podem acessar modelos através da API compartilhada ou implantar sistemas GroqRack dedicados para
Groq
Freemium
Plano Gratuito
API
Empresarial
A Groq hospeda e serve modelos de IA de código aberto em seu hardware LPU customizado, fornecendo infraestrutura de inferência gerenciada que entrega velocidade líder da indústria. As organizações podem acessar modelos através da API compartilhada ou implantar sistemas GroqRack dedicados para
 10
4.2
10
4.2
 Google AI Studio
Gratuito
Plano Gratuito
API
Empresarial
Google AI Studio funciona como uma plataforma de hospedagem gerenciada para modelos Gemini, fornecendo endpoints de inferência da camada gratuita que desenvolvedores podem usar imediatamente. Google gerencia toda a infraestrutura, dimensionamento e disponibilidade, com a opção de fazer a transiç
Google AI Studio
Gratuito
Plano Gratuito
API
Empresarial
Google AI Studio funciona como uma plataforma de hospedagem gerenciada para modelos Gemini, fornecendo endpoints de inferência da camada gratuita que desenvolvedores podem usar imediatamente. Google gerencia toda a infraestrutura, dimensionamento e disponibilidade, com a opção de fazer a transiç
 11
4.0
11
4.0
 Scale AI
Pago
API
Empresarial
A Plataforma de IA Generativa da Scale AI permite que empresas criem, testem e implementem aplicações alimentadas por LLM com ferramentas para engenharia de prompts, avaliação de modelos, gerenciamento de dados de fine-tuning e desenvolvimento de aplicações. A plataforma suporta o ciclo de vid
Scale AI
Pago
API
Empresarial
A Plataforma de IA Generativa da Scale AI permite que empresas criem, testem e implementem aplicações alimentadas por LLM com ferramentas para engenharia de prompts, avaliação de modelos, gerenciamento de dados de fine-tuning e desenvolvimento de aplicações. A plataforma suporta o ciclo de vid