AI-modellhosting - Katalog med AI-anmeldelser
Å kjøre AI-modeller i produksjon krever infrastruktur optimalisert for ventetid, gjennomstrømning og kostnad. Hugging Faces Inference Endpoints og Replicate lar utviklere distribuere hvilken som helst modell bak et REST-API på minutter. Ollama og Together AI gjør det enkelt å kjøre modeller med åpne vekter lokalt eller i skyen, mens Groqs LPU-inferenschips leverer responstider under 100 ms for sanntidsapplikasjoner.
 1
4.8
1
4.8
 Hugging Face
Freemium
Gratis plan
API
Åpen kildekode
Enterprise
Hugging Face er den største åpne plattformen for hosting av AI-modeller, med over 500 000 modeller tilgjengelig for nedlasting og distribusjon. Den tilbyr Inference Endpoints for distribusjon av modeller på dedikert infrastruktur, gratis Inference API for testing og Spaces for hosting interaktive
Hugging Face
Freemium
Gratis plan
API
Åpen kildekode
Enterprise
Hugging Face er den største åpne plattformen for hosting av AI-modeller, med over 500 000 modeller tilgjengelig for nedlasting og distribusjon. Den tilbyr Inference Endpoints for distribusjon av modeller på dedikert infrastruktur, gratis Inference API for testing og Spaces for hosting interaktive
 2
4.8
2
4.8
 OpenAI API Platform
Betalt
API
Enterprise
OpenAI arrangerer og serverer sitt hele AI-modellutvalg gjennom administrert infrastruktur, og håndterer alle aspekter av GPU-provisjonering, skalering og tilgjengelighet. Plattformen tilbyr endepunkter for språkmodeller, bildegenerering, talebehandling og embeddings, med Assistants API som tilbyr
OpenAI API Platform
Betalt
API
Enterprise
OpenAI arrangerer og serverer sitt hele AI-modellutvalg gjennom administrert infrastruktur, og håndterer alle aspekter av GPU-provisjonering, skalering og tilgjengelighet. Plattformen tilbyr endepunkter for språkmodeller, bildegenerering, talebehandling og embeddings, med Assistants API som tilbyr
 3
4.7
3
4.7
 Ollama
Gratis
Gratis plan
Åpen kildekode
Ollama muliggjør lokal modelldrift ved å betjene LLM-er gjennom et REST-API på brukerens egen maskinvare. Dens OpenAI-kompatible API-format gjør det mulig for den å fungere som en lokal modellserver som integreres med utviklingsverktøy, web-grensesnitt og applikasjoner, og tilbyr selvdriftet m
Ollama
Gratis
Gratis plan
Åpen kildekode
Ollama muliggjør lokal modelldrift ved å betjene LLM-er gjennom et REST-API på brukerens egen maskinvare. Dens OpenAI-kompatible API-format gjør det mulig for den å fungere som en lokal modellserver som integreres med utviklingsverktøy, web-grensesnitt og applikasjoner, og tilbyr selvdriftet m
 4
4.7
4
4.7
 Replicate
Betalt
API
Enterprise
Replicate tilbyr en administrert plattform for hosting og serving av AI-modeller via API. Brukere kan distribuere tusenvis av forhåndslaget åpen kildekode-modeller eller publisere sine egne ved hjelp av Cog-containeriseringsverktøyet, med automatisk GPU-forsyning, skalering fra null og betaling p
Replicate
Betalt
API
Enterprise
Replicate tilbyr en administrert plattform for hosting og serving av AI-modeller via API. Brukere kan distribuere tusenvis av forhåndslaget åpen kildekode-modeller eller publisere sine egne ved hjelp av Cog-containeriseringsverktøyet, med automatisk GPU-forsyning, skalering fra null og betaling p
 5
4.6
5
4.6
 Together AI
Betalt
API
Enterprise
Together AI hostar og serverer hundrevis av åpen kildekode-AI-modeller på optimalisert infrastruktur. Utviklere kan distribuere modeller gjennom det delte slutningsAPI-et for kostnadseffektiv betjening eller tildele dedikerte endepunkter for garantert kapasitet, med plattformen som håndterer all
Together AI
Betalt
API
Enterprise
Together AI hostar og serverer hundrevis av åpen kildekode-AI-modeller på optimalisert infrastruktur. Utviklere kan distribuere modeller gjennom det delte slutningsAPI-et for kostnadseffektiv betjening eller tildele dedikerte endepunkter for garantert kapasitet, med plattformen som håndterer all
 6
4.6
6
4.6
 Anthropic API
Betalt
API
Enterprise
Anthropic drifter og serverer alle Claude-modeller gjennom sin forvaltede API-infrastruktur, og håndterer GPU-provisjonering, skalering og pålitelighet. API-en er også tilgjengelig gjennom Amazon Bedrock og Google Cloud Vertex AI, noe som gir utviklere flere hostingalternativer for tilgang til Cl
Anthropic API
Betalt
API
Enterprise
Anthropic drifter og serverer alle Claude-modeller gjennom sin forvaltede API-infrastruktur, og håndterer GPU-provisjonering, skalering og pålitelighet. API-en er også tilgjengelig gjennom Amazon Bedrock og Google Cloud Vertex AI, noe som gir utviklere flere hostingalternativer for tilgang til Cl
 7
4.4
7
4.4
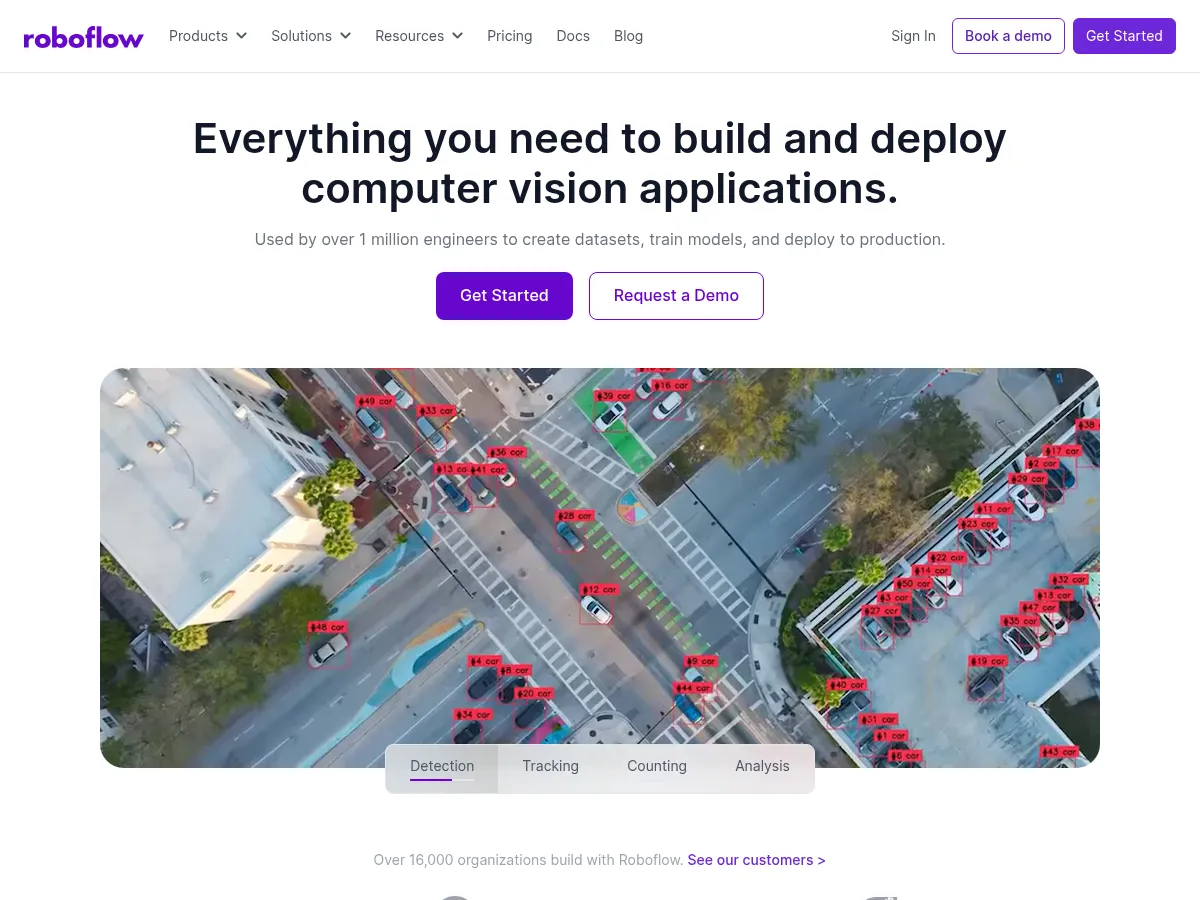
 Roboflow
Freemium
Gratis plan
API
Åpen kildekode
Enterprise
Roboflow tilbyr vertsbaserte inferens-APIer for distribusjon av computer vision-modeller i produksjon, med alternativer for skybasert hosting, edge-distribusjon på enheter som NVIDIA Jetson og Raspberry Pi, og selvbetjent inferens gjennom den åpen kildekode Roboflow Inference-serveren. Denne fleks
Roboflow
Freemium
Gratis plan
API
Åpen kildekode
Enterprise
Roboflow tilbyr vertsbaserte inferens-APIer for distribusjon av computer vision-modeller i produksjon, med alternativer for skybasert hosting, edge-distribusjon på enheter som NVIDIA Jetson og Raspberry Pi, og selvbetjent inferens gjennom den åpen kildekode Roboflow Inference-serveren. Denne fleks
 8
4.4
8
4.4
 Databricks
Betalt
API
Enterprise
Databricks tilbyr modelltjenester gjennom Mosaic AI, og gir administrerte endepunkter for implementering av maskinlæringsmodeller og fundamentale modeller i produksjon. Plattformen støtter sanntids- og batch-inferens, automatisk skalering, A/B-testing og modellovervakning, sammen med Foundation Mo
Databricks
Betalt
API
Enterprise
Databricks tilbyr modelltjenester gjennom Mosaic AI, og gir administrerte endepunkter for implementering av maskinlæringsmodeller og fundamentale modeller i produksjon. Plattformen støtter sanntids- og batch-inferens, automatisk skalering, A/B-testing og modellovervakning, sammen med Foundation Mo
 9
4.4
9
4.4
 Groq
Freemium
Gratis plan
API
Enterprise
Groq driver og betjener AI-modeller med åpen kildekode på sin tilpassede LPU-maskinvare, og tilbyr styrt inferensinfrastruktur som leverer bransjens ledende hastighet. Organisasjoner kan få tilgang til modeller gjennom det delte API-et eller implementere dedikerte GroqRack-systemer for privat mod
Groq
Freemium
Gratis plan
API
Enterprise
Groq driver og betjener AI-modeller med åpen kildekode på sin tilpassede LPU-maskinvare, og tilbyr styrt inferensinfrastruktur som leverer bransjens ledende hastighet. Organisasjoner kan få tilgang til modeller gjennom det delte API-et eller implementere dedikerte GroqRack-systemer for privat mod
 10
4.2
10
4.2
 Google AI Studio
Gratis
Gratis plan
API
Enterprise
Google AI Studio fungerer som en administrert hostingplattform for Gemini-modeller, og tilbyr inferensendepunkter på gratis nivå som utviklere kan bruke umiddelbart. Google håndterer all infrastruktur, skalering og tilgjengelighet, med muligheten til å gå over til Vertex AI for dedikert modelho
Google AI Studio
Gratis
Gratis plan
API
Enterprise
Google AI Studio fungerer som en administrert hostingplattform for Gemini-modeller, og tilbyr inferensendepunkter på gratis nivå som utviklere kan bruke umiddelbart. Google håndterer all infrastruktur, skalering og tilgjengelighet, med muligheten til å gå over til Vertex AI for dedikert modelho
 11
4.0
11
4.0
 Scale AI
Betalt
API
Enterprise
Scale AI's Generative AI Platform gjør det mulig for bedrifter å bygge, teste og distribuere LLM-drevne applikasjoner med verktøy for prompt engineering, modellvurdering, fin-tuning-datahåndtering og applikasjonsutvikling. Plattformen støtter hele livssyklusen fra modellvalg og tilpasning gjenn
Scale AI
Betalt
API
Enterprise
Scale AI's Generative AI Platform gjør det mulig for bedrifter å bygge, teste og distribuere LLM-drevne applikasjoner med verktøy for prompt engineering, modellvurdering, fin-tuning-datahåndtering og applikasjonsutvikling. Plattformen støtter hele livssyklusen fra modellvalg og tilpasning gjenn